스페셜 메서드(매직 메서드)
일반적인 사용자가 정의하여 사용할 수 있는 메서드와 다르게, 스페셜 메서드는 파이썬의 특정한 상황에서 자동으로 사용한다.
또한, __init__, __str__ 처럼 언더스코어 두 개로 시작하고 끝나는 메서드이다.
사용 이유는 “객체의 기본 동작을 커스터마이징 / 사용자 정의 동작을 추가” 하기 위함이다.
기본적으로 우리가 사용하는 많은 객체에는 이러한 스페셜 메서드가 정의되어 있고, 이는 당연스럽게 편리한 사용으로 이어진다.
우리가 문자열을 저장할 때 사용하는 str Object에 대한 정의를 살펴보면, object 를 상속받은 하나의 Class이다.
확인해보면, str 클래스 내 새롭게 정의된 메서드도 여럿 존재하며 object 에서 상속받아 재정의 되거나 새롭게 정의한 다양한 스페셜 메서드가 존재한다.
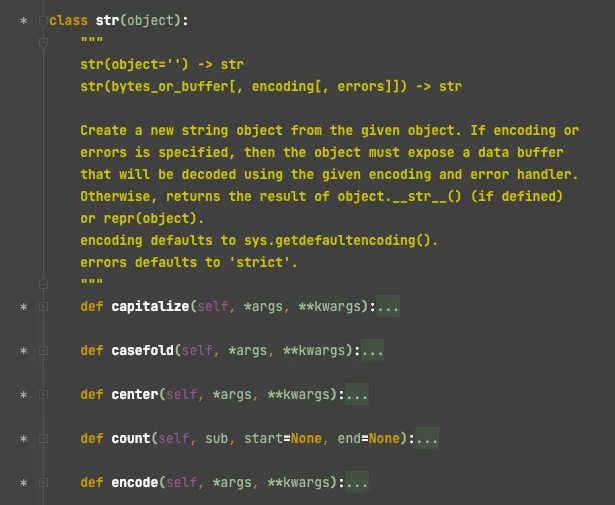
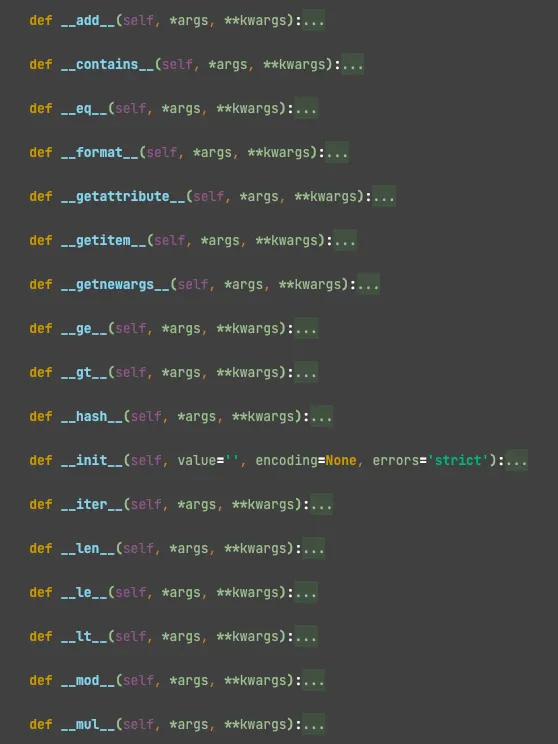
이해를 위한 예시
이렇게 정의된 스페셜 메서드는 아래 예시와 같은 코드가 동작시키며, “파이썬에서는 문자열의 덧셈을 어떻게 인식하고 처리하는 거지?” 라는 의문을 해결해준다
물론 __add__ 의 실제 동작 코드는 C언어로 작성된 파이썬의 인터프리터(CPython)에 정의되어 있기 때문에, str 클래스의 선언 부분에는 작성되어 있지 않다.
# str 클래스의 문자열
str1 = "hello"
str2 = "world"
# str 클래스임을 알 수 있다.
print(type(str1)) # <class 'str'>
print(str1.__class__) # <class 'str'>
# '+' 동작 시 str 클래스 내 정의된
# `__add__` 스페셜 메서드를 사용
print(str1 + str2) # helloworld
Python
복사
즉, 다시 생각해보면 __add__ 가 없다면 위 코드가 정상적으로 동작하지 않을 것 이다.
아래와 같이 str 클래스의 기능 중 __add__ 스페셜 메서드만 다른 동작을 하도록 하는 새로운 문자열을 저장하는 클래스를 만들어 테스트 해보았다.
class str_not_add(str):
"""
__add__ 스페셜 메서드를 변경한 새로운 클래스
"""
def __add__(self, *args, **kwargs):
print("NOT ADD")
# str 클래스의 문자열
str1 = str_not_add("hello")
str2 = str_not_add("world")
# str_not_add 클래스임을 알 수 있다.
print(type(str1)) # <class '__main__.str_not_add'>
print(str1.__class__) # <class '__main__.str_not_add'>
# '+' 동작 시 str_not_add 클래스 내 정의된
# `__add__` 스페셜 메서드를 사용
print(str1 + str2)
Python
복사
아래와 같이 기존의 + 연산이 정상적으로 동작하지 않음을 알 수 있다.
새로운 __add__ 의 동작으로 인한 NOT ADD 출력과, return이 없는 __add__ 의 결과로 None이 Print되었다.

이와 같이, 파이썬에서 기본적으로 제공하는 많은 데이터 타입이 있고 이 데이터 타입들은 인터프리터에 동작이 정의된 여러 스페셜 메서드를 사용하여 정의되었다. (물론 추가적인 자제 메서드도 같이 정의한다.)
공식 문서에 따르면, 적지 않은 스페셜 메서드가 존재한다.
•
+, -, *, @, /, // 등등 연산자 사용 시 동작하는 스페셜 메서드 종류
•
With문 사용 시 동작하는 스페셜 메서드
스페셜 메서드 정리
__missing__
딕셔너리의 존재하지 않는 새로운 key를 확인할 때 동작하는 스페셜 메서드이다.
dict 를 상속받아 __missing__ 스페셜 메서드를 오버라이딩 시, 존재하지 않는 key 확인 시 커스텀한 동작을 진행하도록 만들 수 있다.
Example
__getattr__ vs __getattribute__
객체 내 속성을 조회할 때 사용할 수 있다.
__getattr__
•
객체 내 존재하지 않는 속성을 참조할 때 사용
•
__missing__ 이 딕셔너리의 미 존재키를 조회 시 사용하는 것과 비슷하다.
__getattribute__
•
객체에서 존재하든, 존재하지 않던 속성 조회 시 무조건 호출되는 메서드이다.
•
해당 메서드 내부에서, 추가적인 속성 조회로 루프에 빠지지 않도록 주의해야한다.
Example(무한루프)
namedtuple : label이 존재하는 튜플
namedtuple은 인스턴스처럼 튜플을 생성하여 이름을 사용하여 접근이 가능한 튜플을 의미한다.
선언 시, 여러 옵션을 사용할 수 있지만 기본적으로 아래 예시와 같이 typename 과 field_names 을 설정하여 사용한다.
namedtuple 는 일반 클래스보다 메모리를 덜 사용하며, tuple의 특징인 불변성을 가지고 갈 수 있다는 장점이 있다.
rename 등 인자를 설정하여, 생성된 namedtuple의 이름 변경도 가능하긴 하다.
그 외 module 등 여러 기능도 있으니, 참고 링크를 확인하면 좋을 것 같다.
Example
위치 지정 인자 / 키워드 지정 인자
우리가 메서드 호출 시, 별도의 키워드를 사용하는 경우가 있고 그렇지 않은 경우가 있다.
이는 메서드 정의 시 결정되는데, 많은 인자를 사용하는 메서드의 경우 유지보수 및 사용에 용이하도록 이러한 인자를 상황에 맞게 잘 정의하는 것이 좋다.
이때, / / * 를 사용하여 위치 지정 인자와 키워드 지정 인자를 구분할 수 있는 방법이 있다.
•
위치 전용 인자 (/): 슬래시(/) 앞에 정의된 인자는 반드시 위치 인자로만 전달
•
키워드 전용 인자 (*): 별표(*) 뒤에 정의된 인자는 반드시 키워드 인자로만 전달
•
이는 슬래시(/) 뒤, 별표(*) 앞에 정의된 인자는 위치/키워드 둘다 사용이 가능하다는 의미이다.
Example
이터레이터 프로토콜
이터레이터 프로토콜은 데이터 구조를 순회하는 방법을 정의하며, 파이썬에만 존재하는 개념은 아니다.
효율적이고 유연한 데이터 순회를 할 수 있도록 제공해주며 무엇보다 메모리 절약이 가장 큰 이유이다.
일반적으로 리스트를 사용하면 리스트 전체 크기만큼 공간을 사용하지만, 이터레이터 방식을 사용한다면 순차적으로 필요 시에만 데이터를 적재하기 때문이다.

이렇게 모든 연산을 한번에 처리하지 않고, 필요 시에만 연산을 처리하여 메모리를 절약하는 방법을 느긋한 계산법(lazy evaluation) 이라고도 한다.
이 방식은 대량의 데이터를 순차적으로 처리할 때 자주 사용되는 방식이다.
이 프로토콜에서 사용되는 용어를 간단하게 정리하면 아래와 같다.
•
컨테이너(Container) : 여러 요소를 담을 수 있는 객체로, 이 요소들은 내부에 저장된다.
◦
리스트, 튜플, 딕셔너리 등이 해당
•
이터러블(Iterable) : 이터러블은 __iter()__ 메서드를 사용하여 이터레이터를 반환할 수 있는 구조를 가진 객체인지 여부
◦
실제 객체 자체를 의미하는게 아닌, 위와 같은 성질을 가진 객체가 맞는지 여부를 확인하는 것이다.
파이썬은 일반적으로 컨테이너와 이터러블은 거의 동일한 개념이라고 생각하면 된다.
컨테이너이면서 이터러블이 아닌 자료형은 찾기 어렵기 때문이다.
•
이터레이터(Iterator) : 이터레이터는 __next__() 메서드를 사용하여 순회할 수 있는 객체이다.
◦
순회를 위해 __iter__ / __next__ 를 통한 정의가 필요하다.
•
제너레이터(Generator) : 함수로 작성하며, yield 키워드를 사용하여 값을 생성하고 반환하고 이를 사용해 이터레이터를 생성한다.
◦
이때 yield 키워드를 만나면 __next__() 메서드가 동작되는 방식이다.
◦
() 를 사용하여 test = (item for item in range(10)) 와 같이 Generator 식을 통한 간편한 생성도 가능하다.
▪
리스트 컴프리헨션을 () 로 감싼다고 생각하면 편하다.
이터레이터 vs 리스트
우리가 사용하는 리스트가 반복이 가능하다고 해서 리스트를 이터레이터와 동일하게 생각하는 경우가 있는데, 그렇지 않다.
리스트가 이터러블은 맞지만 두개는 엄밀하게 다른 개념이며, 리스트 next 를 사용한 순회를 시도하면 동작하지 않는다.
또한 리스트는 메모리 절약을 위한 lazy evaluation를 지원하는 방식도 아니다. 사용 시 전체 데이터를 모두 로드한다.
test = [1, 2, 3]
# TypeError: 'list' object is not an iterator
next(test)
Python
복사
For문의 동작 원리
조금 의아할 수 있는게, For문은 Iterator와 리스트 모두 상관없이 동작이 가능하다.
그렇다면 For문은 어떤 순서로 동작하는 것인지 확인해보자
data = [1, 2, 3]
# 여기서 어떻게 data에서 하나씩 데이터를 뽑는걸까...?
for item in data:
...
Python
복사
1.
우선 data.__iter__() 를 사용하여, 해당 데이터의 Iterator를 반환받는다.
•
여기서 헷갈릴 수 있는데, 리스트의 경우 data 와 data.__iter__() 로 반환된 데이터는 다르다.
•
그 이유는 data 자체가 Iterator가 아닌 Iterable 데이터이기 때문이다.
•
만약 data가 이미 Iterator일 경우에는 data 와 data.__iter__() 는 같을 것이다.
2.
1번에서 반환된 Iterator에 정의된 __next__() 를 동작시켜 다음 데이터를 확인 후 For문 내부의 코드 동작
•
한번 더 작성하지만, 리스트의 경우 data 와 data.__iter__() 로 반환된 데이터는 다르다.
•
이 때문에, data.__next__() 는 없지만, data.__iter__().__next__() 는 존재한다.
•
따라서, 리스트에서도 For문의 사용이 가능한 것 이다.
3.
다음 요소를 찾을 수 없을 경우의 StopIteration가 Raise 되면 break
이터레이터 / 제너레이터 사용법
이를 위해서는 위에 작성한 내용처럼 __iter__ / __next__ 를 통해 정의된 객체를 만들거나, 제너레이터를 사용해야한다.
Example (Iterator 정의)
Example (Generator 정의)
주의점
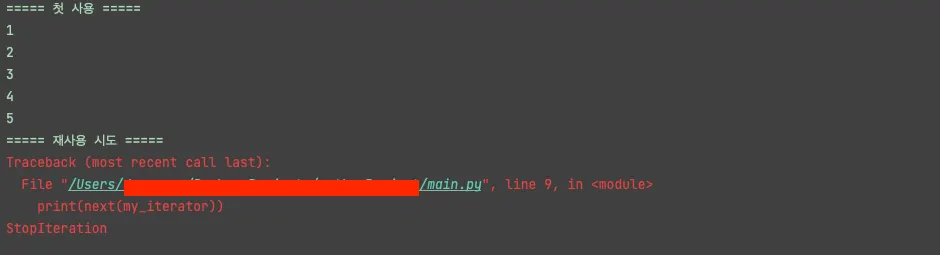
이터레이터는 한번 순회되면 재사용이 안되는 성질을 가지고 있다.
이미 한번 전체 순회가 끝난 이터레이터를 next 를 사용한다면 StopIteration가 Raise된다.
my_iterator = iter([1, 2, 3, 4, 5])
print("===== 첫 사용 =====")
for i in my_iterator:
print(i)
print("===== 재사용 시도 =====")
print(next(my_iterator))
Python
복사
이런 문제가 발생할 수 있는 상황이 있는데, 바로 특정 메서드의 인자로 이터레이터를 사용하는 경우이다.
인자로 받은 이터레이터를 메서드 내부에서 여러번 재사용을 시도하는 경우, 메서드가 정상적으로 동작하지 않는 경우가 있다.
아래는 __iter__() / __next__() 를 사용한 순회를 사용하는 sum() / for 를 동시에 사용하는 메서드의 예시를 작성하였다.
sum() 에서 순회가 끝나면서, 이후 For문에서는 정상적으로 동작하지 않는다.
여기서 문제점은, For문 영역에서 StopIteration가 Raise가 되지 않는다는 점이다.
즉, 에러로 확인이 되지 않는 상황이기 때문에 차후 문제가 발생하여도 빠른 디버깅이 어려울 수 있다.
따라서 인자로 Iterator를 사용할 때는 각별한 주의가 필요하다.
def test_method(iterator):
# Iterator내 모든 값을 더한 값을 출력
print(sum(iterator))
# Iterator내 값들을 순차적으로 출력
# 이미 순회가 끝난 Iterator는 For문이 동작하지 않는다.
for item in iterator:
print("순회 중 & 출력: ", item)
# Iterator 생성
data = iter([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
test_method(data)
Python
복사

지금처럼 메서드 내부에서 Iterator를 재사용하는 상황을 만들고 싶을때는 sum() / for 문 처럼 순회가 필요한 상황마다 별도의 Iterator를 생성해주는 방식을 사용한다.
이를 방지하기 위해서는 아래 2가지 방법 중 하나를 사용해야한다.
1.
메서드 내, 재사용이 될 가능성이 있는 Iterator는 iter() 를 사용한 데이터인지 확인
•
type() 을 사용한 검사가 가능하며, 상황에 따라 Raise를 동작 시키면 좋을 듯 하다.
2.
매번 새로운 Iterator를 반환할 수 있는 __iter__() 메서드가 정의된 Iterator를 사용
•
이를 위해서는 이전처럼 __iter__() 현 객체(self)를 반환하는게 아닌, Generator에 사용되는 코드(yield 키워드 사용)를 설정하여 호출마다 다른 Iterator를 반환하도록 만든다.
Example (__iter__() 커스텀)
Class와 Interface의 사용
클래스 메서드를 사용한 다형성 적용
보통 많은 인터페이스를 가진 클래스라면, 여러 계층의 클래스를 가진 구조로 사용될 수 있다.
만약 아래와 같은 방식으로 구조를 짜게 된다면 어떨까?
아래 예시는 동물 이름을 리스트로 전달하면, 관련 Class를 Worker로 생성 후 Thread로 동작(speak method)하는 구조이다.
Example
위 예시는 당연히 정상적으로 동작한다. 여기서 Dog뿐 아니라 새로운 동물인 Cat이 동일하게 동작하도록 추가해야한다면 어떨까?
generate_workers 메서드를 다시 확인해보면, Dog class만 동작하도록 설정된 것을 알 수 있다.
Worker를 반환하기 위해서는 리스트에 객체를 append 해야하지만, 파이썬은 생성자를 __init__ 하나만 지원하기 때문에 객체를 넣기 위해서는 클래스를 직접 설정하여 객체를 만들어야한다.
이렇게 제너릭하지 않은 경우에는 타 객체를 위한 별도의 메서드를 계속 만들어야하는 단점이 발생한다.
def generate_workers(name_info):
"""
name_info에 있는 이름들을 가지고 Worker 객체를 생성합니다.
:param name_info: 동물 이름 리스트
:return: worker 객체 리스트
"""
workers = []
for name in name_info:
workers.append(Dog(name))
return workers
# 절망편...(Cat 이라는 새로운 클래스의 Worker를 반환)
# 이렇게 별도의 메서드를 쓰거나, 기존 메서드에 분기를 넣어야한다.
def generate_workers_for_Cat(name_info):
"""
name_info에 있는 이름들을 가지고 Worker 객체를 생성합니다.
:param name_info: 동물 이름 리스트
:return: worker 객체 리스트
"""
workers = []
for name in name_info:
workers.append(Cat(name))
return workers
Python
복사
이를 개선하기 위해서는 @classmethod 를 사용해볼 수 있다.
특정 클래스의 __init__ 를 직접 사용하여 객체를 만드는게 아닌, 클래스 메서드를 사용하여 간접적으로 사용하는 것이다.
Example(@classmethod 적용)
아래와 같이, 각 Class에 객체 생성을 위한 별도의 제너레이터를 클래스 메서드로 선언하였다.
class Dog(Animal):
...
@classmethod
def generate_worker(cls, name_info):
yield from (cls(name) for name in name_info)
class Cat(Animal):
...
@classmethod
def generate_worker(cls, name_info):
yield from (cls(name) for name in name_info)
Python
복사
이를 사용하여, 특정 클래스를 동작하기 위한 별도의 메서드를 각각 생성하지 않고 제너릭하게 여러 클래스를 지원할 수 있게 되었다.
def generate_workers(input_class, name_info):
"""
name_info에 있는 이름들을 가지고 Worker 객체를 생성합니다.
:param input_class: Worker 객체를 생성할 클래스
:param name_info: 동물 이름 리스트
:return: worker 객체 리스트
"""
return list(input_class.generate_worker(name_info))
...
# Animal Class를 상속받은 클래스라면, `map_speak` 메서드를 모두 사용 가능
map_speak(Dog, ["Buddy", "Max", "Charlie"])
map_speak(Cat, ["Lucy", "Chloe", "Bella"])
Python
복사
디스크립터를 사용한 속성(애트리뷰트)접근 커스텀
디스크립터는 파이썬에서 속성(애트리뷰트)의 접근 하는 방법을 직접 커스텀하는 방식이며, __set__ / __get__ / __delete__ 셋 중 하나라도 정의한 디스크립터 클래스를 속성에 사용하여 적용한다.
기존의 Object에서 속성(애트리뷰트)에 접근 시, 아래와 같은 동작이 진행된다.
•
object.attribute (접근)
1.
object의 클래스의 __dict__ 를 확인하여, attribute 가 존재하는지 확인
2.
attribute.__get__(instance, owner) 가 동작, 이때 instance 에는 obj가 전달되며 owner 에는 Class 가 전달된다.
•
object.attrubute = 100 (수정)
1.
object의 클래스의 __dict__ 를 확인하여, attribute 가 존재하는지 확인
2.
attribute.__get__(instance, value) 가 동작, 이때 instance 에는 obj가 전달되며 value 에는 100이 전달된다.
이러한 원리를 사용해서, __get__ , __set__ 등 매직메서드를 정의된 별도의 클래스를 정의하는데 이를 디스크립터 클래스라고 한다.
from weakref import WeakKeyDictionary
class Grade:
def __init__(self):
self._values = {}
def __get__(self, instance, instance_type):
if instance is None:
return self
return self._values.get(instance, 0)
def __set__(self, instance, value):
if not (0 <= value <= 100):
raise ValueError('점수는 0과 100 사이입니다')
self._values[instance] = value
class Exam:
math_grade = Grade()
writing_grade = Grade()
science_grade = Grade()
first_exam = Exam()
first_exam.writing_grade = 82
first_exam.science_grade = 99
Python
복사
하나씩 내용을 살펴보면, 먼저 Grade 를 Exam 의 속성에서 사용하는 방식이다. 즉, Grade 가 디스크립터 클래스이다.
디스크립터 사용의 주의점
디스크립터 클래스를 속성에 설정할 때 주의점이 있다.
이는 굳이 Grade 에서 각각의 value 를 인스턴스별로 나눠서 저장하는지 확인해보면 알 수 있는데, 이유는 첫 Exam 생성 후 다른 Exam 이 생성되더라도 동일 속성은 똑같은 Grade 를 사용하기 때문이다.
아무리 여러 Exam 인스턴스를 만들어도, 결국에는 Exam 의 동일 속성을 가진 경우라면 같은 Grade 를 공유한다.
exam1.math_grade 와 exam2.math_grade 는 같은 Grade 라는 의미이다.
In [27]: exam1 = Exam()
In [28]: exam2 = Exam()
In [29]: exam1.__class__.__dict__
Out[29]:
mappingproxy({'__module__': '__main__',
'math_grade': <__main__.Grade at 0x7f96d06d0700>,
'writing_grade': <__main__.Grade at 0x7f96d06d7130>,
'science_grade': <__main__.Grade at 0x7f96d06d7c10>,
'__dict__': <attribute '__dict__' of 'Exam' objects>,
'__weakref__': <attribute '__weakref__' of 'Exam' objects>,
'__doc__': None})
In [30]: exam2.__class__.__dict__
Out[30]:
mappingproxy({'__module__': '__main__',
'math_grade': <__main__.Grade at 0x7f96d06d0700>,
'writing_grade': <__main__.Grade at 0x7f96d06d7130>,
'science_grade': <__main__.Grade at 0x7f96d06d7c10>,
'__dict__': <attribute '__dict__' of 'Exam' objects>,
'__weakref__': <attribute '__weakref__' of 'Exam' objects>,
'__doc__': None})
Python
복사
이 이야기는, 아래와 같이 서로 다른 인스턴스임에도 속성 수정 시 영향을 줄 수 있다는 것이다.
아래 예시 처럼 exam1.math_grade 의 초기 설정 후, exam2.math_grade 를 변경하였지만 exam1.math_grade 에도 영향을 줄 수 있는 것이다.
In [31]: exam1.math_grade = 100
In [32]: exam2.math_grade = 50
In [33]: exam1.math_grade
Out[33]: 50
Python
복사
이를 예방하기 위해서는, Grade 에서 value 하나의 값을 저장하는 방식이 아닌 dict 방식을 사용하여 Exam 인스턴스마다 다른 값을 저장하도록 구성해야한다.
class Grade:
def __init__(self):
self._values = {}
def __get__(self, instance, instance_type):
if instance is None:
return self
return self._values.get(instance, 0)
def __set__(self, instance, value):
if not (0 <= value <= 100):
raise ValueError('점수는 0과 100 사이입니다')
self._values[instance] = value
...
Python
복사
WeakKeyDictionary
이제 위 내용으로 디스크립터 클래스에서 왜 값을 저장할 때 dict 등 자료형을 사용하여 인스턴스 별로 데이터를 구분하여 저장하는게 안전한지 알 수 있었을 것이다.
하지만, 단순히 dict 를 사용하면 문제가 있다. 바로 메모리가 누수(낭비)된다는 점이다.
파이썬의 가비지 컬렉터는 특정 참조에 대한 카운트를 저장하는데, 이 카운트가 없는 경우(0)에만 해당 메모리를 재활용한다.
즉, 더 이상 참조를 안하는 객체에 대한 메모리를 해제하고 다른 데이터를 설정하는 것이다.
이 카운트는 강한 참조의 갯수를 확인한다.
만약 dict 로 _values 를 구성한다면, 해당 인스턴스의 Grade 디스크립터 클래스를 사용하는 속성의 모든 값을 초기화 하지 않으면 강한 참조는 풀리지 않을 것이다.
...
# 모든 참조 제거
first_exam = Exam()
first_exam.writing_grade = 82
first_exam.science_grade = 99
# 딕셔너리 내부의 모든 참조 제거
first_exam.math_grade._values = {}
first_exam.writing_grade._values = {}
first_exam.science_grade._values = {}
# 딕셔너리를 참조하는 변수 제거
del first_exam
Python
복사
하지만, WeakKeyDictionary를 사용한다면 각 Exam 에서 Grade 를 참조하는 모든 속성의 값을 초기화하지 않더라도 del 을 통한 변수 제거만 되어도 메모리가 재사용 가능하다.
왜냐하면, WeakKeyDictionary 는 강한 참조가 아닌 약한 참조로 Exam 의 속성과 연결되어있기 때문에 참조 카운트로 집계하지 않기 때문이다.
즉 Exam 변수가 사라져 해당 참조만 사라진다면, 내부 속성의 각 참조는 연쇄적으로 해제될 것이다.
from weakref import WeakKeyDictionary
class Grade:
def __init__(self):
self._values = WeakKeyDictionary()
...
Python
복사
__set_name__을 사용하여 속성 이름 동적 설정
주로 디스크립터에서 사용할 수 있는데, 디스크립터 클래스의 속성명을 편리하게 정의하기 위해 사용한다.
Example
__new__ / __init_subclass__ 를 사용한 서브클래스 검증
클래스를 생성하고 관리할 때 사용되는 메타클래스는 type 에 의해 정의되며, __new__ 메서드를 통해 작성한 메타클래스를 사용하는 하위 클래스의 정보를 받는다.
이때 __new__ 는 클래스 정의 시, 정확하게는 클래스 객체가 생성될 때 호출되기 때문에 __init__ 를 사용한 객체 생성 전 하위 클래스 자체를 검증할 수 있다.
만약 검증을 위해 __new__ 등을 사용한다면, 이 상황을 위해 별도의 검증 전용 메타 클래스를 만들고, 그 클래스를 하위 클래스의 메타 클래스로 설정해야하는 불편함이 있다.
•
type 을 상속받는 메타클래스 / 메타클래스를 사용하는 Base 클래스 / 이 Base 클래스를 상속받는 하위 클래스
이를 개선하고자, __init_dubclass__ 라는 스페셜 메서드를 사용하여 이를 대신할 수 있다.
Example(__init_dubclass__ 사용 예시)
물론 검증이 아니더라도, 클래스 정의 시 필요한 동작이 있다면 검증 로직을 대신하여 사용하면 된다.
커스텀 컨테이너 타입 사용
collections.abc를 활용한 구현
일반적으로 파이썬에서 지원하는 컨테이너 자료형을 본인만의 원하는 커스텀으로 사용하는 경우가 많다.
이때, collections.abc 를 활용하여 자신이 구현하고 싶은 자료형에 기본적으로 필요한 메서드를 알 수 있다.
물론 collections의 UserDict처럼 기존 컨테이너 자료형을 확장하여 만드는 방법도 있지만, 커스텀 자료형에서는 필요한 최소한의 기능만 가져오는 것이 유지보수에 용이하다.
이 내용이 어떤 의미인지 헷갈릴 수 있다.
나는 custom_dict[key] 로 조회만 가능한 Dict를 만들고 싶은 상황이라면, __getitem__ 매직 메서드만을 사용하여 커스텀한 자료형을 만들 수 있을 것이다.
하지만, 위와 같은 상황에서 UserDict 를 상속받아 사용한다면 불필요한 DIct의 여러 기능까지 상속 받는 상태가 된다.
이는 파이썬스러운 코드가 아니며, 차후 커스텀 자료형의 기능 변경 및 확장에도 좋지 않다.
만약, 내가 Sequence의 성질을 가지는 커스텀 자료형을 만들고 싶다면 아래와 같이 어떤 메서드가 필요한지 알 수 있다.
아래 예시를 통해, Sequence의 성질을 가지는 커스텀 자료형 제작에는 __getitem__ / __len__ 의 매직 메서드 구현이 필요함을 알 수 있다.
from collections.abc import Sequence
class CustomType(Sequence):
"""아무것도 구현하지 않은 Class"""
pass
# Can't instantiate abstract class CustomType with abstract methods __getitem__, __len__
data = CustomType()
Python
복사
동시성/병렬성 작업 처리
subprocess란
현재 진행중인 프로세스에서 또 다른 프로세스를 시작하거나 데이터를 주고 받고자 만들어진 모듈이다.
별도의 프로세스를 만들기 때문에, 만들어진 프로세스와 현 작업은 당연히 병렬성을 가진다.
이 모듈을 사용하는데에는 여러 방법이 있다.
1.
간단한 프로세스의 실행을 위한 subprocess.run()
CompletedProcess 객체를 반환하며, stdout / stderr / returncode 등 기본적인 정보를 확인할 수 있다.
Example
2.
비동기적 실행 + 파이프라인 처리를 위한 subprocess.Popen()
CompletedProcess 객체와 동일하게 stdout / stderr / returncode 등 기본적인 정보를 확인할 수 있으며, poll() / wait() 등 현재 실행시킨 프로세스에 대한 추가적인 동작을 처리할 수 있는 메서드가 별개로 존재한다.
Example
Lock 이란
파이썬은 레이스 컨디션과 같은 상황을 최대한 막고, Blocking I/O 작업 시 다른 작업을 수행하기 위해 GIL이라는 시스템을 사용하고 있다.
이를 통해, 하나의 스레드만이 바이트 코드를 실행할 수 있도록 처리할 수 있도록 하고있다.
 Python Enhancement Proposals (PEPs)PEP 703 – Making the Global Interpreter Lock Optional in CPython | peps.python.org
만약 PEP 703이 적용된다면, GIL을 강제가 아닌 선택사항으로 변경하는 내용이 반영 예정이라고 한다.
Python Enhancement Proposals (PEPs)PEP 703 – Making the Global Interpreter Lock Optional in CPython | peps.python.org
만약 PEP 703이 적용된다면, GIL을 강제가 아닌 선택사항으로 변경하는 내용이 반영 예정이라고 한다.하지만 아무리 GIL을 사용한다고 해도, 레이스 컨디션을 완전히 막기는 어렵다.
아래 코드는 하나의 클래스에 존재하는 count 속성 값을 5개의 스레드에서 빠르게 증가 처리하는 예시이다.
동작을 해보면, 당연히 매 동작마다 다르겠지만 원하는 증가 횟수와 실제 결과가 다른 것을 알 수 있다.
Example(Race Condition 발생)
그 이유는 self.count += 1 이라는 작업이 원자적인 연산이 아니기 때문이다.
self.count += 1 아래 3가지 작업을 통해 진행되는 연산이다.
1.
self.count 값을 읽는다.
2.
self.count 값에 1을 더한다.
3.
더한 값을 self.count 값에 쓴다.
GIL의 특징은 “여러 스레드가 동시에 바이트코드를 실행하지 못하게 하는 것” 이다.
하지만, 아래와 같은 상황이 되면 어떨까?
1.
A스레드의 1번 작업(self.count 값을 읽기)
2.
B스레드의 1번 작업(self.count 값을 읽기)
3.
A스레드의 2번 작업(self.count 값에 1을 더함)
4.
A스레드의 3번 작업(self.count 값에 더한 값을 쓴다.)
5.
B스레드의 2번 작업(self.count 값에 1을 더함)
6.
B스레드의 3번 작업(self.count 값에 더한 값을 쓴다.)
GIL은 정상적으로 A와 B스레드에 나눠서 바이트 코드를 실행시켜주었다.
하지만 위 순서대로 동작된다면, A/B 스레드는 동일한 숫자 값에 1을 더해주는 상황이된다.
즉, 2개의 스레드에서 +1 작업을 하였지만 실제 데이터는 +2가 아닌 +1만 되는 것이다.
그래서 Lock이라는 방식(뮤텍스 락 참고)를 통하여, self.count += 1 이 진행되는 3가지 작업을 하나의 원자적인 작업으로 만들 수 있다.
Lock을 가지고 있는 스레드만이 해당 코드를 동작시킬 수 있고, 다른 스레드는 Block되기 때문이다.
한마디로 with 문을 통해, self.count += 1 이 진행되는 3가지 작업을 임계구역으로 만든 것이다.
Lock()은 __enter__, __exit__ 사용하여 acquire / release 를 처리가 가능하기 때문에 with 문을 사용하면, 간편하게 임계구역을 설정할 수 있다.
아래 코드 동작 시, 정상적으로 모두 숫자 증가 처리가 된 것을 알 수 있다.
Example(Lock 설정)