모델 개요
OpenAI API는 다양한 기능과 가격대의 모델들로 구동됩니다. 또한, 특정 사용 사례에 맞게 모델을 맞춤화할 수 있는 미세 조정 기능도 제공합니다.

Last Update : 2024-06-13
MODEL | DESCRIPTION |
GPT-4o | 가장 빠르고 가장 저렴한 플래그십 모델 |
GPT-4 Turbo and GPT-4 | 이전의 고지능 모델 세트 |
GPT-3.5 Turbo | 간단한 작업을 위한 빠르고 저렴한 모델 |
DALL·E | 자연어 프롬프트를 주면 이미지를 생성하고 편집할 수 있는 모델 |
TTS | 텍스트를 자연스럽게 들리는 음성 오디오로 변환할 수 있는 모델 세트 |
Whisper | 오디오를 텍스트로 변환할 수 있는 모델 |
Embeddings | 텍스트를 수치 형식으로 변환할 수 있는 모델 세트 |
Moderation | 텍스트가 민감하거나 안전하지 않을 가능성을 감지할 수 있는 미세 조정된 모델 |
GPT base | 지시를 따르지 않지만 자연어 또는 코드를 이해하고 생성할 수 있는 모델 세트
→ 간단하게 말하면 예전에 사용한 GPT-3 Base 모델이다. |
GPT-4o
GPT-4o(“o”는 “omni”의 약자)는 2024-06월 기준으로 가장 진보된 모델입니다.
이 모델은 멀티모달로, 텍스트나 이미지 입력을 받아들이고 텍스트를 출력합니다.
GPT-4 Turbo와 동일한 높은 지능을 갖추고 있지만, 훨씬 더 효율적입니다. 텍스트를 2배 더 빠르게 생성하며 비용이 50% 저렴합니다.
위 내용은 OpenAI사의 설명이지만, 조금 더 찾아보니 기존 GPT4 / GPT4-Turbo보다 모든 면에서 상위호환이라고 느낀 것은 아니었다.

위 커뮤니티의 내용을 정리하면 아래와 같았다.
기존 GPT-4 라인의 기능은 개선이 되었지만, 만약 작업이 복잡한 경우라면 기존의 GPT4-Turbo / GPT4가 더 좋은 결과를 주고 있다는 의견이 있었다.
즉, 일상적으로 사용하는 간단한 질문이나 채팅(비언어권)은 비용과 효율성이 더 좋은 GPT-4o를 쓰고 복잡한 데이터를 다룬다면 기존 라인을 써도 좋을 것 같다.
기능 | GPT-4 | GPT-4o |
복잡한 작업 처리 | 우수, 복잡한 작업에서 뛰어남 | 열등, 복잡한 분석에 약함 |
프롬프트 정확성 | 높음, 프롬프트를 잘 따름 | 낮음, 때때로 관련 없는 출력 생성 |
효율성 | 표준 | 2배 빠르고, 비용 50% 절감 |
이미지 읽기 | 좋음 | 뛰어남, 상당한 개선 |
비영어권 언어 성능 | 좋음 | 모델 중 최고 성능 |
적합성 | 정밀한 읽기와 분석에 최적 | 비용 효율성과 단순 작업에 최적 |
2024년 5월쯤부터 ChatGPT의 무료 사용 시에도 GPT-4o를 사용할 수 있게 되었는데, 기존 GPT4는 아직 유료로 금액을 지불해야 사용이 가능하다.
이는 GPT4가 유료 버전에만 제공되어야하는 어떠한 이유가 있는게 아닐까?
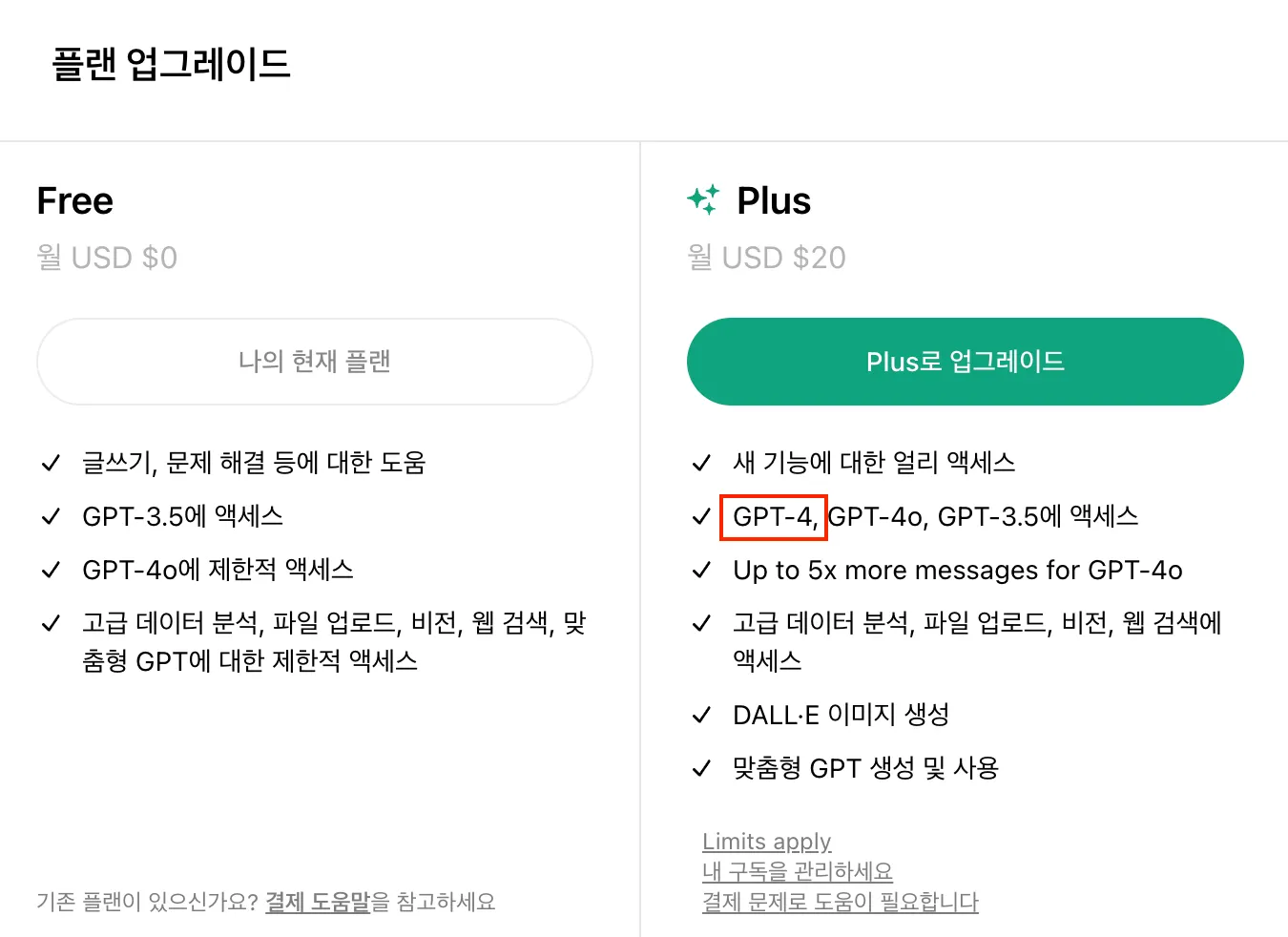
자세한 내용은 아래 내용을 읽으면 좋다.
GPT4 Turbo / GPT-4
이전 GPT-3는 이미지 등 입력을 처리하지 못하였지만, GPT-4는 텍스트나 이미지 입력을 받아들이고 텍스트를 출력할 수 있도록 만들어진 대형 멀티모달 모델입니다.
이 모델은 넓은 일반 지식과 고급 추론 능력을 통해 이전 모델들보다 더 높은 정확도로 어려운 문제를 해결할 수 있습니다.
GPT-3 / GPT-3.5 Turbo
ChatGPT의 유행이 시작되었을 때, 가장 대중적으로 사용되었던 모델이다.
현재는 더 뛰어난 GPT-4 라인 모델이 출시되었고, GPT-4라인의 하위호환이라고 생각하면 된다.
성능상으로도 동일 기능에서 차이가 있지만, 가장 큰 차이점은 이미지/음성을 입력 프롬포트로 사용하지 못한다는 것이다.
DALL·E
DALL·E는 자연어로 된 설명을 바탕으로 현실적인 이미지와 예술 작품을 생성할 수 있는 AI 시스템입니다.
현재 DALL·E 3는 주어진 프롬프트에 따라 특정 크기의 새로운 이미지를 생성할 수 있는 기능을 지원합니다. DALL·E 2는 기존 이미지를 편집하거나 사용자가 제공한 이미지의 변형을 생성하는 기능도 지원합니다.
DALL·E 2와 DALL·E 3는 기능의 차이가 있는데, 가장 큰 차이는 “기존 이미지의 편집 가능 여부” 이다.
DALL·E 3에서는 오히려 해당 기능을 지원하지 않는다.
이유는 “기존 이미지의 편집” 작업은 상당한 리소스가 필요하기 때문에, DALL·E의 목적인 “고품질 이미지 생성”에 더 포커스를 맞춰 개발을 하고 있고, DALL·E 3가 이러한 OpenAI사의 의도에 맞게 출시된 모델이다.
자세한 내용은 아래 내용을 읽으면 좋다.
 OpenAIDALL·E 3
OpenAIDALL·E 3
TTS
TTS는 텍스트를 자연스러운 음성으로 변환하는 AI 모델입니다. 저희는 두 가지 다른 모델 변형을 제공합니다.
tts-1은 실시간 텍스트-음성 변환 사용 사례에 최적화되어 있으며, tts-1-hd는 품질에 최적화되어 있습니다.
이 모델들은 Audio API의 Speech 엔드포인트에서 사용할 수 있습니다.
TTS는 아직 GPT / DALL·E와 같이 신규 라인이 나온 상태는 아니다.
Whisper
Whisper는 범용 음성 인식 모델입니다.
다양한 오디오 데이터셋을 기반으로 훈련되었으며, 다국어 음성 인식, 음성 번역, 언어 식별 등 여러 작업을 수행할 수 있는 멀티태스크 모델입니다.
Whisper v2-large 모델은 현재 API를 통해 whisper-1 모델 이름으로 제공되고 있습니다.
현재 Whisper의 오픈 소스 버전과 API를 통해 제공되는 버전 사이에는 차이가 없습니다.
하지만 API를 통해 제공되는 최적화된 추론 프로세스를 사용하면 다른 방법보다 Whisper를 더 빠르게 실행할 수 있습니다. Whisper에 대한 기술적 세부 사항은 논문에서 확인할 수 있습니다.
간단하게 말해서, TTS와 반대 작업을 하는 모델이다.
Embeddings
임베딩은 두 텍스트 간의 관련성을 측정하는 데 사용할 수 있는 텍스트의 수치적 표현입니다. 임베딩은 검색, 클러스터링, 추천, 이상 감지 및 분류 작업에 유용하다.
다른 페이지에도 정리해두었으니, 참고하면 좋을 것 같다.
Moderation
Moderation 모델은 OpenAI의 사용 정책 준수 여부를 확인하도록 설계되었습니다.
이 모델들은 증오, 증오/위협, 자해, 성적, 성적/미성년자, 폭력, 폭력/그래픽 등의 카테고리에서 콘텐츠를 분류합니다.
모더레이션 모델은 임의 크기의 입력을 받아 4,096 토큰으로 자동으로 분할합니다.
입력이 32,768 토큰을 초과하는 경우, 드문 상황이지만 일부 토큰이 생략될 수 있습니다.
요청 결과는 각 카테고리별로 최대 값을 보여줍니다.
예를 들어, 하나의 4K 토큰 덩어리가 0.9901, 다른 하나가 0.1901의 점수를 가졌다면, API 응답은 0.9901을 표시합니다.
GPT Base
GPT 기본 모델은 자연어 또는 코드를 이해하고 생성할 수 있지만, 지시를 따르도록 훈련되지 않았습니다.
이 모델들은 원래의 GPT-3 기본 모델을 대체하기 위해 만들어졌으며, 레거시 Completions API를 사용합니다.
대부분의 고객은 GPT-3.5 또는 GPT-4를 사용하는 것이 좋습니다.
즉, 예전에 사용했던 자연어를 이해하고 생성할 수 있는 모델이다.
다만 이제는 레거시 API를 사용하기 때문에 최신 GPT 모델을 사용하는 것을 권장한다.